Wprowadzenie
SEO (Search Engine Optimization) to szereg działań mających na celu zwiększenie widoczności strony internetowej w wynikach wyszukiwania. Dwa kluczowe procesy, które odgrywają fundamentalną rolę w tym obszarze, to crawl-owanie i renderowanie. Chociaż oba terminy brzmią technicznie, ich zrozumienie jest kluczowe dla właścicieli stron internetowych, specjalistów SEO oraz wszystkich, którzy chcą zoptymalizować swoje strony dla wyszukiwarki Google. W tym artykule wyjaśnimy, czym są te procesy, jak działają oraz jak można je poprawić, aby zwiększyć efektywność działań SEO.
Crawl-owanie i Renderowanie – Spis treści:

Czym jest crawl-owanie?
Crawl-owanie (z ang. „crawling”) to proces skanowania i indeksowania stron internetowych przez roboty wyszukiwarek (tzw. crawlers, spiders lub bots). Googlebot i inne roboty przeszukują internet w poszukiwaniu nowych treści oraz aktualizacji istniejących stron. Crawl-owanie odgrywa kluczową rolę w procesie pozycjonowania stron internetowych, ponieważ tylko zaindeksowane strony mogą pojawiać się w wynikach wyszukiwania.
Google i inne wyszukiwarki posiadają specjalne algorytmy, które decydują o tym, jak często i które strony powinny być skanowane. Strony o wysokiej jakości treści, częstych aktualizacjach i dobrej strukturze linkowania są odwiedzane częściej niż te o niskiej wartości.
Jak wygląda proces crawl-owania?
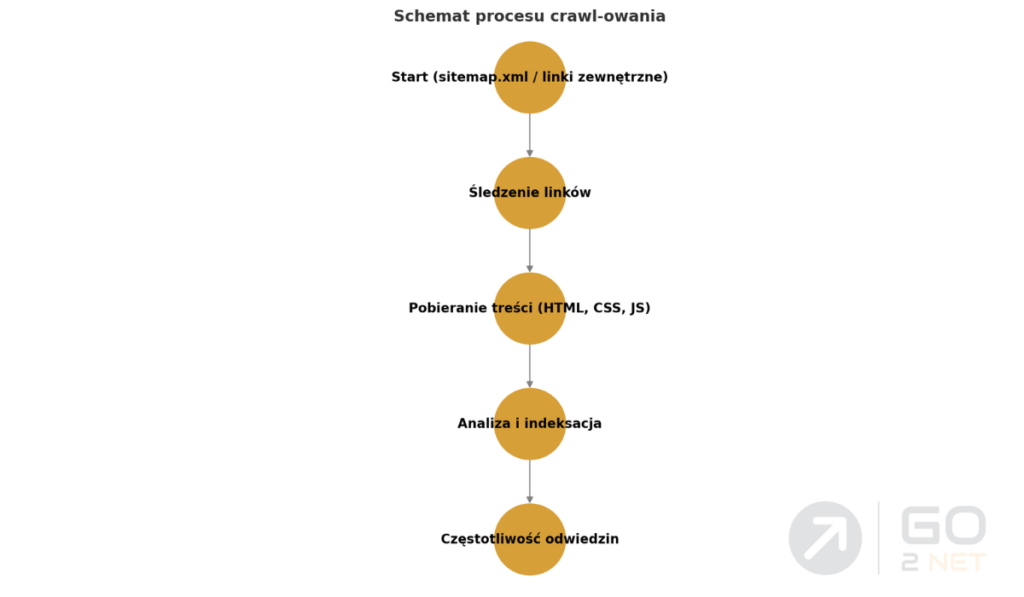
Proces crawl-owania składa się z kilku etapów:
- Odwiedzanie strony początkowej – Googlebot rozpoczyna od stron, które zna, takich jak te zgłoszone w pliku sitemap.xml lub te, do których prowadzą linki z innych witryn.
- Śledzenie linków – robot analizuje linki wewnętrzne i zewnętrzne, aby odkryć kolejne strony do odwiedzenia. Mocno powiązane strony są indeksowane szybciej.
- Pobieranie treści – Googlebot pobiera kod HTML, pliki CSS, JavaScript oraz inne zasoby niezbędne do analizy strony.
- Analiza treści – robot ocenia strukturę strony, obecność tagów meta, nagłówków, grafik i innych elementów, aby określić jej wartość i tematykę.
- Dodanie do kolejki indeksowania – jeśli strona spełnia wymagania jakościowe, jej treść zostaje zapisana i może trafić do indeksu Google.
- Częstotliwość ponownego odwiedzania – w zależności od częstotliwości aktualizacji treści na stronie, Googlebot decyduje, jak często powraca na daną stronę.
Jak przyspieszyć crawl-owanie swojej strony?
Jeśli chcesz, aby Googlebot częściej odwiedzał Twoją stronę i szybciej indeksował nowe treści, warto zastosować kilka sprawdzonych metod:
- Zgłoszenie strony w Google Search Console – możesz ręcznie dodać nową stronę do indeksu Google, co przyspieszy jej pojawienie się w wynikach wyszukiwania.
- Stworzenie i optymalizacja mapy witryny (sitemap.xml) – dobrze przygotowana mapa witryny ułatwia robotom odnalezienie nowych i zaktualizowanych treści.
- Użycie wewnętrznego linkowania – łączenie nowych stron z już zaindeksowanymi pomaga Googlebotowi szybciej odkrywać nowe podstrony.
- Regularna aktualizacja treści – strony, na których często pojawiają się nowe artykuły lub zmiany w treści, są odwiedzane częściej.
- Optymalizacja prędkości ładowania strony – strony o szybkim czasie ładowania są bardziej przyjazne dla Googlebota i użytkowników.
- Unikanie duplikatów treści – zduplikowane treści mogą negatywnie wpłynąć na częstotliwość crawl-owania i ranking strony.
Dzięki tym działaniom możesz zwiększyć szanse na szybsze i bardziej efektywne indeksowanie swojej witryny, co pozytywnie wpłynie na jej pozycjonowanie w Google.
Jeśli chcesz dowiedzieć się więcej o tym, jak zgłosić stronę do GSC, jak zoptymalizować indeksację strony i skutecznie zarządzać procesem crawl-owania, zapraszamy do przeczytania naszego artykułu: Poprawne crawlowanie Googlebota.

Czym jest renderowanie?
Renderowanie (z ang. „rendering”) to proces, w którym wyszukiwarka przekształca kod HTML, CSS i JavaScript w widok podobny do tego, co widzi użytkownik na ekranie przeglądarki. Dzięki temu Google może lepiej zrozumieć treść strony i określić jej wartość. Współczesne strony internetowe często korzystają z dynamicznych technologii, takich jak JavaScript, które wymagają dodatkowego przetworzenia przed pełnym zaindeksowaniem.
Jak działa renderowanie?
- Pobranie kodu strony – Googlebot pobiera kod HTML oraz odwołania do plików CSS i JavaScript.
- Analiza kodu – robot sprawdza strukturę strony i uruchamia JavaScript, aby wczytać dynamiczne elementy.
- Symulacja przeglądarki – Googlebot renderuje stronę tak, jak widzi ją użytkownik w Chrome. W ten sposób wyszukiwarka może ocenić układ strony, interaktywne elementy i poprawność wyświetlania treści.
- Zapisanie treści w indeksie – po analizie strona zostaje dodana do indeksu wyszukiwarki, co pozwala na jej wyświetlanie w wynikach wyszukiwania.
Problemy z renderowaniem
- Zbyt duża ilość JavaScript – Google może mieć trudności z renderowaniem dynamicznych stron.
- Blokowanie zasobów w pliku robots.txt – jeśli Google nie ma dostępu do CSS i JavaScript, może nie zobaczyć pełnej wersji strony.
- Długi czas ładowania strony – renderowanie może się nie udać, jeśli strona ładuje się zbyt wolno.
- Nieprawidłowe użycie AJAX – treści ładowane asynchronicznie mogą być niewidoczne dla wyszukiwarek.
Jeśli chcesz dowiedzieć się więcej o renderowaniu dynamicznym i jego wpływie na indeksację w Google, warto zapoznać się z materiałem przygotowanym przez Google, który szczegółowo opisuje ten proces.
Dlaczego crawl-owanie i renderowanie są ważne dla SEO?
Zrozumienie procesów crawl-owania i renderowania ma kluczowe znaczenie dla optymalizacji SEO. Jeśli roboty wyszukiwarek nie są w stanie poprawnie odczytać strony lub nie mogą jej wyrenderować, strona może nie zostać poprawnie zaindeksowana, a tym samym nie pojawi się w wynikach wyszukiwania.

Poniżej przedstawiamy kilka czynników, które mogą utrudniać efektywne crawl-owanie i renderowanie strony:
- Problemy z plikiem robots.txt – jeśli blokujesz Googlebota w pliku robots.txt, wyszukiwarka może nie mieć dostępu do strony.
- Brak optymalizacji dla urządzeń mobilnych – Google preferuje strony dostosowane do wyświetlania na telefonach i tabletach.
- Zbyt duża liczba przekierowań – nadmierna ilość przekierowań może wydłużyć czas ładowania strony i zniechęcić roboty do jej indeksowania.
- Zablokowane pliki JavaScript i CSS – jeśli Googlebot nie może ich odczytać, może błędnie zinterpretować wygląd i funkcjonalność strony.
Poprawna optymalizacja tych elementów może przyspieszyć indeksowanie strony oraz zwiększyć jej widoczność w wynikach wyszukiwania, jednocześnie pomagając w efektywnym zarządzaniu budżetem crawl-owania (Crawl Budget). Im lepiej zoptymalizowana strona, tym bardziej efektywnie Googlebot wykorzysta przydzielony zasób czasu na jej skanowanie, zamiast marnować go na nieistotne lub trudno dostępne treści. O Crawl Budget napiszemy poniżej, a teraz przyjrzyjmy się porównaniu, które pomoże lepiej zrozumieć różnice między crawl-owaniem a renderowaniem.
Crawl-owanie i renderowanie – kluczowe różnice
| Crawl-owanie | Renderowanie |
| Skanowanie kodu strony przez roboty wyszukiwarki | Tworzenie wizualnego widoku strony przez wyszukiwarkę |
| Wykorzystywane do indeksowania treści | Pomaga w interpretacji dynamicznych elementów strony |
| Może być blokowane przez robots.txt | Może być ograniczone przez JavaScript i CSS |
| Kluczowe dla szybkości indeksacji | Kluczowe dla poprawnego wyświetlania strony w wyszukiwarce |
Czym jest Crawl Budget?
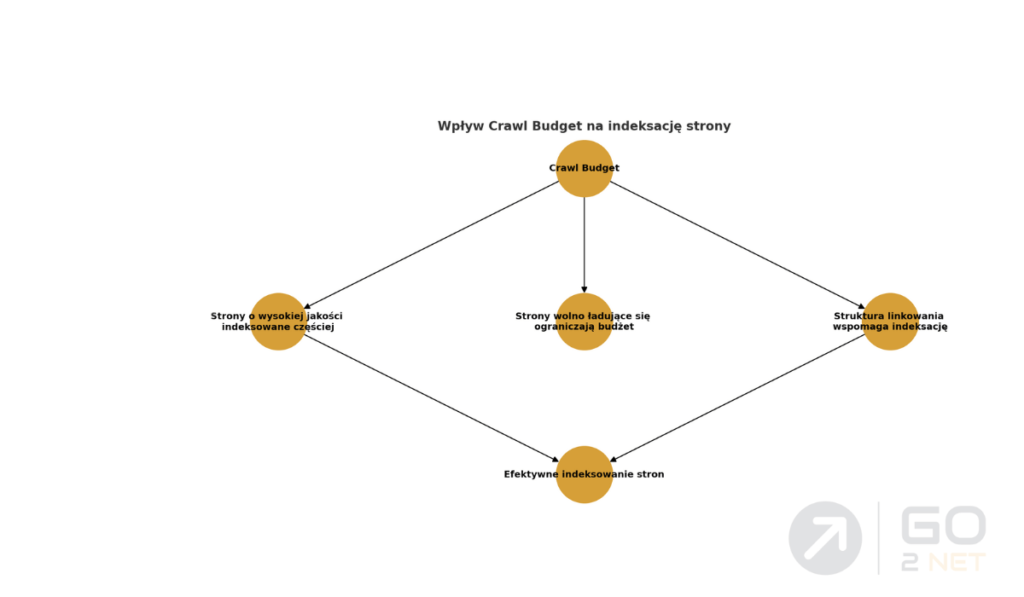
Crawl Budget to ilość zasobów (czasu i liczby stron), które wyszukiwarka przeznacza na skanowanie danej witryny w określonym czasie. Jest to kluczowy czynnik wpływający na częstotliwość odwiedzin botów wyszukiwarki oraz indeksowanie nowych i zaktualizowanych treści.
Co wpływa na Crawl Budget?
- Autorytet strony – strony o wysokim autorytecie (np. duże portale informacyjne) są crawlowane częściej.
- Wydajność serwera – strony ładujące się wolno mogą mieć ograniczony budżet crawl-owania.
- Struktura linkowania wewnętrznego – dobrze zoptymalizowane linkowanie ułatwia botom dotarcie do wszystkich stron.
- Błędy w indeksacji – strony z dużą liczbą błędów 404 lub przekierowań 301 mogą być crawlowane rzadziej.
- Zbyt duża liczba nieistotnych stron – strony niskiej jakości, duplikaty lub strony bez wartościowej treści mogą marnować crawl budget.
Jak zoptymalizować Crawl Budget?
- Usuwanie zbędnych stron – eliminacja stron niskiej jakości poprawia efektywność crawl-owania.
- Optymalizacja pliku robots.txt – warto blokować crawlowanie stron, które nie powinny być indeksowane.
- Używanie tagów canonical – wskazanie kanonicznych adresów URL pomaga w uniknięciu duplikacji treści.
- Poprawa szybkości strony – wolno ładujące się strony mogą powodować wcześniejsze zakończenie crawl-owania przez Googlebota.
- Unikanie nadmiernej ilości przekierowań – wielopoziomowe przekierowania mogą negatywnie wpłynąć na budżet crawl-owania.

Crawl-owanie i Renderowanie – Podsumowanie
Crawl-owanie i renderowanie to dwa kluczowe procesy w SEO. Crawl-owanie pozwala wyszukiwarkom odkryć i zindeksować strony, podczas gdy renderowanie pomaga im zrozumieć, jak wygląda strona dla użytkowników. Dodatkowo, optymalizacja Crawl Budget pozwala na bardziej efektywne wykorzystywanie zasobów wyszukiwarki, co przekłada się na lepszą widoczność w wynikach wyszukiwania.
Dzięki stosowaniu najlepszych praktyk, takich jak poprawa szybkości strony, optymalizacja JavaScript oraz przemyślane linkowanie wewnętrzne, możesz zwiększyć szanse na wysoką pozycję w Google i dotrzeć do większej liczby użytkowników.
Masz pytania dotyczące crawl-owania i renderowania? Skontaktuj się z nimi!